(*不建议核函数计算较快(<0.1s)的使用本程序。感谢@苹果*)
RebootLaunchKernels[n___] := (
CloseKernels[];
LaunchKernels[n];);
bootParallelMonitor[n___] := (
(*清除旧定义*)
UnsetShared[$Proc];
Clear[$Proc];
(*判定是否需要重启内核*)
If[$KernelCount < 2,
RebootLaunchKernels[n],
If[IntegerQ[n] \[And] (n =!= $KernelCount),
RebootLaunchKernels[n], Null],
RebootLaunchKernels[n]];
(*建立并行计算监视器*)
$Proc = ConstantArray[0., $KernelCount + 1];
SetSharedVariable[$Proc];
Column@
Table[With[{m = m}, Dynamic[$Proc[[m]]]], {m,
1, $KernelCount + 1}]);
$KernelMonitor[id_] := Module[{},(*分类累加器*)If[IntegerQ[id] \[And] (id > 1),
$Proc[[Mod[id, $KernelCount] + 1]] += 1, Null];
(*主累加器*)
$Proc[[$KernelCount + 1 + 0*id]] += 1;
(*被并行执行的核函数*)
$Parallelfn];
运行示例:
bootParallelMonitor[]
fn := Cos[i];
$Parallelfn =
Hue[(Arg[fn] + \[Pi])/(2 \[Pi]), 1/(1 + 0.3 Log[Abs[fn] + 1]),
1 - 1/(1.1 + 5 Log[Abs[fn] + 1]), 1];
ParallelTable[$KernelMonitor[i], {i, -20, 20 ,0.1}, Method -> "CoarsestGrained"]
测速:
$Parallelfn = Sum[i, {i, 1000000}];
getData[n_] :=
AbsoluteTiming[
Short[ParallelTable[#[i], {i, n}]]] & /@ {$KernelMonitor} //
Flatten;
getData1[n_] :=
AbsoluteTiming[
Short[ParallelTable[#[i], {i, n}]]] & /@ {$Parallelfn} //
Flatten;
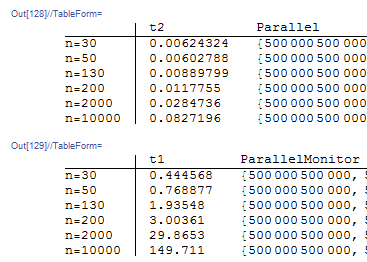
TableForm[getData1 /@ {30, 50, 130, 200, 2000, 10000},
TableHeadings -> {{"n=30", "n=50", "n=130", "n=200", "n=2000",
"n=10000"}, {"t2", "Parallel"}}]
TableForm[getData /@ {30, 50, 130, 200, 2000, 10000},
TableHeadings -> {{"n=30", "n=50", "n=130", "n=200", "n=2000",
"n=10000"}, {"t1", "ParallelMonitor"}}]
结果是挺令人懵逼的。我正在考虑找另外的途径来实现这个目的,而不是用动态更新。。